

Different Selection of .net Data Structure Has a Positive Impact on Performance
January 11, 2024
Today, programmers often fail to consider the performance impact of certain programming choices. Computers have, and continue to, advance and their seemingly unlimited memory results in a programmer’s lack of programming considerations. In one of my recent projects, I had to search reference data from multiple large lists of data (between 500 – 4000 entries in each list) from a numeric ID field in another large list of objects. In this blog, I will explore the positive impacts a different selection of .net data structure can have on performance.
Adopting the standard naive approach of storing the reference data in a List and then using a LINQ query to retrieve them took multiple seconds to complete. In some cases, 10-plus seconds – an eternity for something so simple. The solution was simple and involved utilizing a different data structure to hold the reference data: a Dictionary (or a Lookup in some cases). The time was reduced from ten plus seconds to instant. This was initially surprising but makes sense when considering the differences between a List and a Dictionary. The main difference is the cost incurred to search the List which is on avg O(n) due to traversing the list and comparing each object inside, whereas a Dictionary uses on avg O(1) where it directly accesses the desired object via a distinct hash made of the key value used.
This led me to investigate the performance differences in various scenarios. I wrote a quick program to search Product data for several Invoices. Pictured below are the results comparing Dictionaries and Lists using BenchmarkDotNet to track performance.
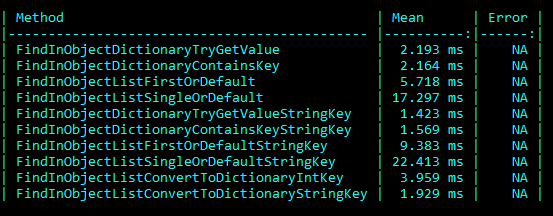
Invoice list size 500, List/Dictionary of Products size 2000:
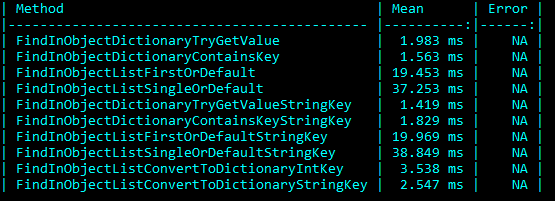
Invoice list size 1000, List/Dictionary of Products size 2000:
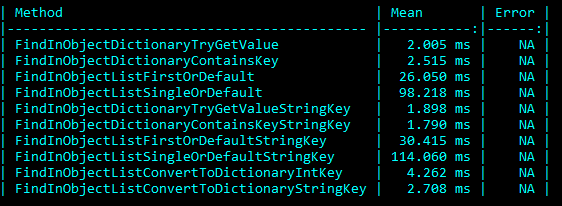
Invoice list size 500, List/Dictionary of Products size 10000:
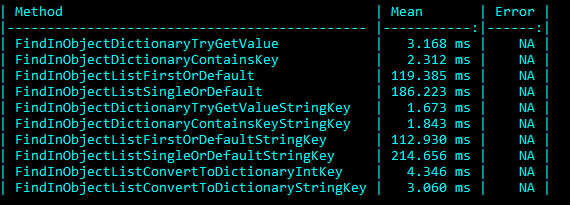
Invoice list size 1000, List/Dictionary of Products size 10000:
The data in the test was simple. It was a Product object defined below:

As well as Invoice objects defined below:

The two different searches were initially performed by using the Product ID to search the Product in the reference list. Next, tests suffixed with String Key used the Product Description to look up the Product. The results are interesting but not unexpected based on the performance expectations of the two data structures. As both the Invoice and Product list size grew, the time to search for them grew proportionally. Whereas the dictionary look-up time was, for the most part, constant. Surprisingly, converting the List using the ToDictionary method to perform the lookups added little time to the overall run time. Comparing the LINQ function FirstOrDefault and SingleOrDefault is an additional interesting performance consideration. The difference between the two is the SingleOrDefault must always traverse the whole list (or until it finds a duplicate of the first result), while FirstOrDefault returns immediately upon locating the first item. If there’s no need to enforce the uniqueness of the lookup it is better to use FirstOrDefault.
There are downsides to any program or technology and Dictionary is no exception. One such downside is that you can’t have key collisions, but with .net there is a data structure called a Lookup. A Lookup is essentially a Dictionary containing Lists under each value, allowing it to store multiple results for the same key definition. Although I didn’t test the performance of using a Lookup, it should be like a Dictionary in terms of the initial lookup. However, subsequently searching through the list will depend on how many elements are in each resulting list. I will demonstrate this in a future post.
The purpose of this blog is to highlight the optimizations and performance implications that had to be considered due to slower hardware are still important to consider and apply to modern applications. The simple change in how we store our lookup reference data has led to a drastic performance change of saving multiple seconds. Initially, these changes may not seem significant, but throughout thousands of requests, those seconds easily add up. Something as simple as choosing a different selection of .net data structure can have significant impacts for any programmer.
At Imaginet, our developers pride themselves on staying updated on all the industry trends. We are fortunate to employ developers who investigate new and innovative ways to improve performance and save valuable time.
If you have an Application Development project in mind, we’d love to hear from you. Fill out the form below and one of our Business Development Representatives will be in touch. Subscribe to our blog for more helpful tips, tricks, and information.
Discover More

Innovation Starts with Listening: Co-Creating Software with End Users
Innovation is key. But with our race to innovate, it’s tempting to focus on speed, features, and technical brilliance. But the most transformative software solutions often don’t begin with code,…

Imaginet in Action: Building Software That Solves Real Problems
Organizations are under a lot of pressure to modernize, scale, and innovate fast. Especially with how rapidly technology is evolving. Many people fall into the trap of thinking that all…

Tech Designed for Local Communities: How Software Can Drive Meaningful Change
It’s common for people to feel like technology creates distance or negatively affects connection. Technology is all about efficiency, efficiency, efficiency. But what if we shifted our mindset? Among all…

Let’s build something amazing together
From concept to handoff, we’d love to learn more about what you are working on.
Send us a message below or call us at 1-800-989-6022.