
Data Architecture & Engineering
Business decisions require data that is accurate and timely. However, often the data needed lives across a variety of business system data bases that make is challenging to write reports against. Imaginet’s Data Architecture and Engineering can help you create a data model that enables the reports you want, when you want them, with a high degree of data confidence.
Data Architecture and the Implementation of
an Enterprise Data and Analytics Environment
Our Approach
Imaginet Data Architecture and Engineering has adopted the principles of Agile Analytics, as best described by Ken Collier’s book “Agile Analytics: A Value-Driven Approach to Business Intelligence and Data Warehousing” We value quality, velocity, and the ability to adapt to change in our development practices. We ensure that our practices allow us to change whatever we need to at any point of a project, with confidence and high quality.
Imaginet has had broad experience and a high level of success with various clients and projects, implementing the best patterns and practices and continually refining and improving our approach. We consistently deliver business value in our projects early and often, and help our customers improve their data analytics environments with clear and concise data models that are easily consumable by end-users and other systems.
This means that data engineering work is done separately from data modelling, and report authoring is done independently from the data model.
Our solutions are well-architected so that each layer is well-defined, is self-contained, and has minimal dependencies. We believe in establishing clear separation of concerns, so that different types of development and authoring can take place by different groups of users, but that teams can collaborate well and react quickly and easily to changes. This means that data engineering work is done separately from data modelling, and report authoring is done independently from the data model.
While Power BI can be used for data engineering (Power Query), data modelling (tables and measures), and data visualizations (reports and dashboards), this approach tends to work well only for small, short-lived data analytic efforts, and becomes unwieldy for long-term enterprise efforts. Many of our client successes have resulted because our client has come to Imaginet with a complex and heavyweight Power BI model and we have industrialized their processes by splitting them out of Power BI, and then giving the report authors a more generalized data model that they can build many standard reports from. This still allows power users to have their own data mashups by extending the enterprise data models with their own supplementary data.
Data Architecture Patterns for Standard Solutions
Imaginet has implemented data engineering, data warehouse, data model, and report authoring solutions using a set of source code projects and code patterns for many of its customers. We have refined these patterns and practices for each engagement to have a continuously improving process, while allowing us to customize each project for the specific data needs of the customer. For example, we have projects for retailers, wholesale distributors, mortgage lenders, academic institutions, and investment and asset management companies, but each database project uses similar patterns for staging data, handling slowly changing dimensions, processing data from structured files such as JSON or CSV, and providing appropriate interfaces to the consumers of the data (such as Power BI data models, tabular models, or ad-hoc SQL users.
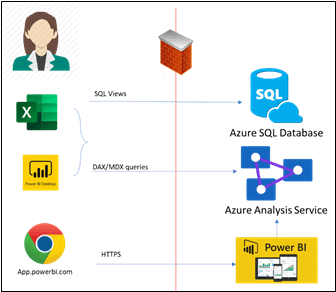
Our typical architecture maximizes the use of Microsoft Azure cloud resources, including Azure SQL, Azure Synapse, and Azure Data Lakes for data storage, Azure Data Factory for ETL processes, and various other types of Azure resources for security and functionality purposes, such as Azure Key Vault, Azure Functions, and Azure Analysis Services. Azure is a highly secure cloud service, and all communication is encrypted, as well as all data at rest, which is encrypted by default (or can be configured to be encrypted). Azure resources are highly scalable and elastic, so they can be configured to be as small or large as needed, when needed; they can scale up to handle increases in workloads and scale down again as the workloads decrease. Much of the management requirements for similar on-premises resources, such as SQL Server, are no longer applicable to Azure-based resources. While performance, tuning, and optimization of SQL databases is still preferred, Azure-based SQL databases can be much more easily tuned and scaled to the actual workloads they are experiencing. In comparison, on-premises SQL Servers, do not easily or quickly allow you to add memory, processors, or disk space, and you lack the flexibility to reallocate resources that you no longer need, which would result in an overall cost savings.
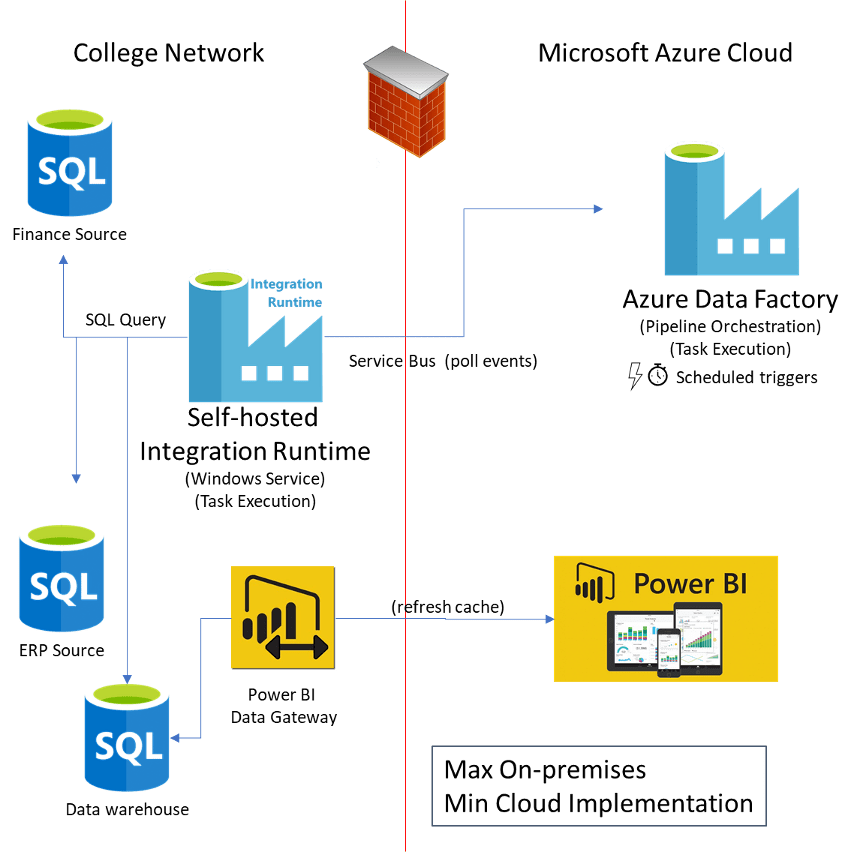
In the figure below, the data architecture uses an on-premises SQL Server instance for hosting the data warehouse database and uses Azure Data Factory and its on-premises agent, the self-hosted integration runtime (IR), to extract data from on-premises (and external) resources, such as SQL databases or file systems, and to transform it into the target database, a data warehouse. In this case, the on-premises IR performs all the data queries within the college network (reads and writes) and the cloud-based Azure Data Factory instance is only orchestrating the tasks within the pipeline. Power BI datasets are connected to the internal data warehouse via a Power BI data gateway that performs all data queries against the internal data sources locally, and the cached data is stored in the Power BI service. To use a client’s on-premises SQL Server instance for the data warehouse, this architecture would be used.
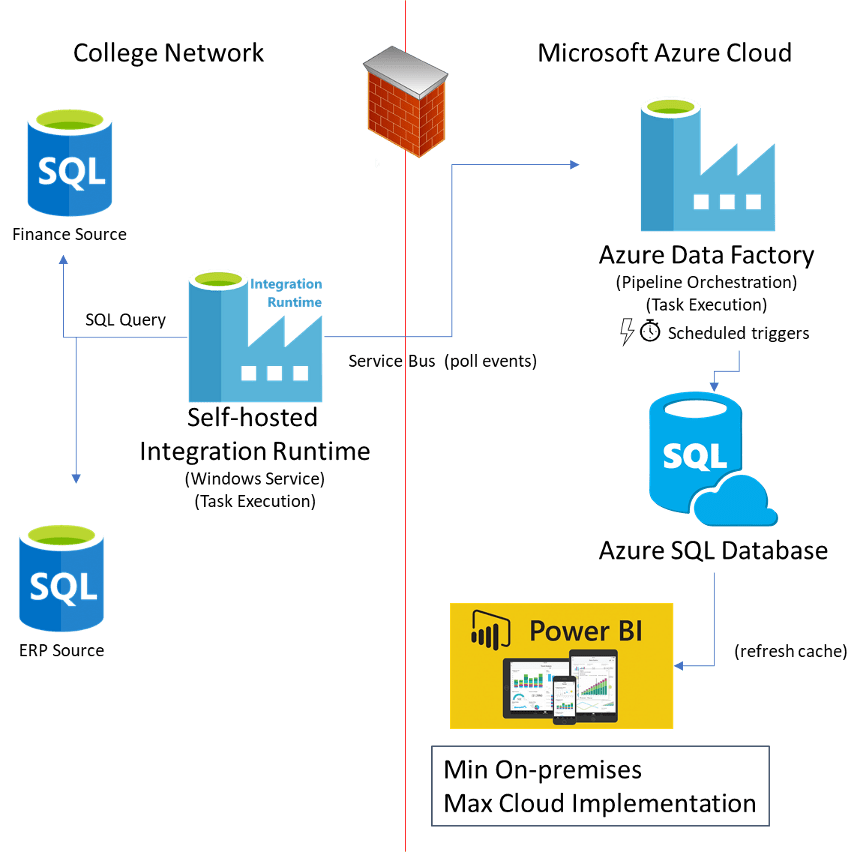
The architecture below, Imaginet’s preferred approach, uses an Azure SQL Database to host the data warehouse. The data flow between the data sources on the corporate network is still handled by the on-premises IR, but the target is now an Azure SQL Database. These databases are limited to an empty IP whitelist by default, so the College network public Internet IP address (or range) would need to be configured on the Azure SQL virtual server instance for the databases to be accessible to the IR. Power BI datasets that use the data warehouse would not need to use a Power BI Data Gateway and likely the Azure SQL Database and the Power BI dataset would be in the same Azure data center, leading to very high performance for refreshing Power BI.
Database Projects and Refactoring
We use database projects in Visual Studio as the repository for data warehouse objects and use the deployment tools for those projects to deploy changes to existing data warehouses. Database projects support various refactoring operations which allows us to respond to database schema changes very quickly and with a high level of confidence and quality. We can add a new table, view, stored procedure, or other object into the database project, or we can make changes (such as renaming a table or a column) and ensure that all references to that table or column are also changed and the project compiles successfully before we attempt to deploy it. The deployment tools also manage renaming operations; for example, a column in a table in the project can be renamed from Postdate to PostingDate, and when that source code is deployed to an instance of database, the deployment process will rename the column PostDate, rather than drop the PostDate column and add a new column PostingDate.
Using database projects brings the value of source code control including historical changes and rollback processes to databases and when combined with DevOps processes to automate database deployments, database schemas can be changed quickly and easily and with a full understanding of the dependencies on the changes, and with confidence that changes will not break existing assets unexpectedly.
Metadata-driven Extract/Load/Transform (ELT) Pipelines
Our Azure Data Factory pipelines are driven by metadata stored in the data warehouse so that once a pipeline is built to support loading from one source into the data warehouse, any additional data that needs to be loaded from that same source is now a matter of adding a row to a table in the data warehouse that contains the metadata. No further pipeline development is needed. Once a metadata-driven pipeline is built for one source, it can handle many data extraction tasks from that source.
On-premises ETL development using SQL Server Integration Services (SSIS) packages, by comparison, requires development changes and package deployment for every data transformation or metadata change, such as adding a new source query or table, or the addition or removal of columns from the source system to an existing transformation. Multiple developers using SSIS packages in Visual Studio concurrently often causes problems integrating changes between team members that can cause quality issues, breakage of ETL processes, loss of development time, and additional deployment time.
Using a metadata-driven approach to ETL with Azure Data Factory increases developer velocity significantly.
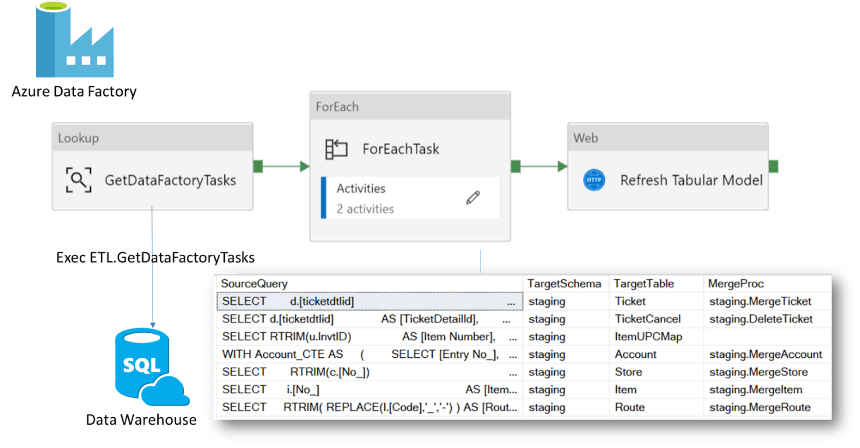
Metadata-driven Azure Data Factory pipeline pattern
Azure DevOps
Imaginet uses Microsoft Azure DevOps (https://dev.azure.com) for source code repositories, work item (task) tracking, and build and release pipelines. Azure DevOps has five free basic licences and unlimited stakeholder licences, and Visual Studio MSDN licences also include access to Azure DevOps. Imaginet’s consultants all have their own MSDN licence. Basic licences include access to the source code repositories and are intended for developer use. Stakeholder licences provide access to the work items and build and release pipelines and are intended for roles such as project managers and users who wish to see the work items and progress boards, such as project stakeholders. Additional basic licences can be purchased for approximately $6 per month.
Imaginet will work with each client to create a new account in Azure DevOps and configure a new Agile project in that account, associated with that client’s Azure Active Directory tenant. If the client already uses Azure DevOps, we can use that account for this project.
Imaginet’s deep experience with Azure DevOps brings significant benefits to this project; primarily, it supports an Agile methodology and DevOps processes to increase team velocity and quality. This means that the development lifecycle for our client’s data analytics in this project is highly optimized to deliver real business value early and often and with high confidence and quality.
Continuous Integration/Continuous Deployment (CI/CD)
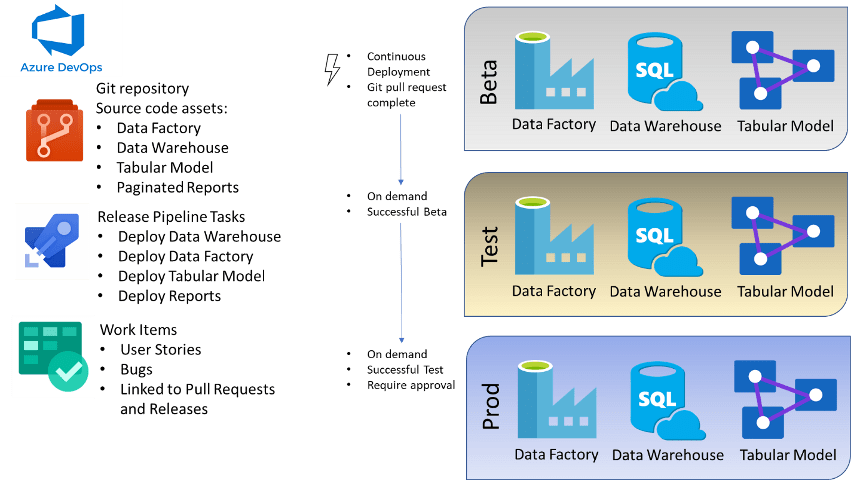
We have standard build and release pipelines that we build in Azure DevOps for deployment of data analytics assets such as data warehouses, Azure Data Factory pipelines, and tabular data analytics models. Once code changes to the database or pipeline or other assets has been reviewed and successfully compiled through a Pull Request, they can be deployed immediately to an initial environment (we call this Beta, to ensure that a deployment is successful) and then subsequently to a test environment (we call it UAT, short for User Acceptance Testing) for full data validation. After acceptance testing has passed the UAT build, the Prod deployment can be executed with confidence that the approved assets are reliably deployed to the production environment. This is often referred to as CI/CD (Continuous Integration/Continuous Deployment).
Imaginet’s team velocity for DevOps is fastest when an Azure-maximized architecture is used. However, we have also implemented the same architecture with using on-premises SQL Server instances for the data warehouse. Azure DevOps release pipelines can use an on-premises agent to deploy to resources (such as SQL Databases) that are only available on the internal (private) client network, given the appropriate permissions in the target database or on the target server. Usually, the primary constraint for automated deployment of databases to an on-premises SQL Server is the reluctance of DBAs to allow such deployments to occur automatically.
Azure Release pipelines can be configured to required approval of deployments by various people, prior to and/or after deployments have occurred in an environment (such as Beta, UAT, or Production).
Work Item Tracking and Source Code Repositories
We use work items in Azure DevOps to track functional and system requirements and tasks for design, development and validation of work. When developers check in code changes to the source code repositories, a policy requires them to associate one or more work items, and that the check in gets reviewed by someone else (most often the Imaginet senior data engineer assigned to the project), and that the code compiles successfully. When these policies are enforced, they are a gate that ensures only high quality code is checked in.
When checked in code is deployed with Azure DevOps release pipelines, the associations of work items made in the checkins is maintained, so each release has a list of work items that were implemented in the changed code. This provides auditing capabilities to determine who made what code changes, and when and where the code has been deployed.
Power BI
Imaginet has worked with Power BI since its inception. We have established best practices for the dataset, and report and dashboard development, and focus especially on providing clear and concise datasets that are easily understood by end-users, to foster the adoption of a self-service data analytics environment.
In addition to Power BI Pro, we have worked with our clients to use the advanced features of Power BI Premium workspaces. We have leveraged XMLA Endpoints in Premium workspaces to deploy tabular models (SSAS Tabular databases), to separate data analytical models from reporting and visualization (these two layers are combined by default in a Power BI Desktop data model). We have also deployed these same models to Azure Analysis Services, the cloud version of SQL Server Analysis Services. We have also deployed RDL report definitions (SQL Reporting Services and Power BI Paginated Reports) to Premium workspaces, using Azure DevOps release pipelines. We have also had experience with monitoring Premium capacity workloads across multiple Power BI workspaces, to identify data models that are consuming the most and least resources.
A key function that Power BI Premium enables is an XMLA endpoint, so that a Tabular data model (SSAS Tabular project) can be deployed to a Premium-enabled workspace. This type of project is functionally equivalent to the data model portion of a Power BI Desktop file, so using this project establishes a clear separation of the data model from the reporting and visualization of data, built in Power BI Desktop. Secondly, data models in the Tabular data project (and deployed to XMLA) have greater control for data refresh operations and may be desirable for incrementally refreshing Power BI data. For example, a large data model may not need to have the entire dataset refreshed, but only the most recent week or day of data.
Power BI Pro and Premium workspaces support Paginated Reports, essentially a Power BI-hosted instance of SQL Server Reporting Services, which may be useful for shared operational reporting. Paginated Reports are designed for printing, as opposed to Power BI reports and dashboards, which are intended to be interactive on screen and not printed.
Premium capacities remove the user licencing requirement for Power BI Pro licences for viewer access to Power BI workspaces. Those users who publish in Power BI workspaces or require Contributor, Member, or Admin role membership in a Power BI workspace still require a Pro licence.
The decision to use Power BI Premium capacities, or Power BI Premium Per User, or Power BI Pro licencing models, is determined by cost and use of features. Typically, if there are about 250 or more users in the organization that would only require viewer access to Power BI assets, then a Power BI Premium capacity is typically a cost-saving. Even when using Premium capacity licencing, there is still a need for Power BI Pro licences for anyone who will be authoring or managing Power BI assets.
Business decisions require data that is accurate and timely. However, often the needed data exists in a variety of spreadsheets, databases, and cloud systems that make it challenging to write reports against. Imaginet’s Data Engineering can help you create a data model that enables the reports you want, when you want them, with a high degree of data confidence.
discover more
A leading institute specializing in food science consulting wanted their content to be accessible as part of a Retrieval-Augmented Generation (RAG) application designed to support…
A major Canadian University wanted to automate the process of reporting endowment fund expenditures to faculties. The proceeds of endowment funds are used to support…
A well-known consumer packaged goods (CPG) company specializing in pet food asked Imaginet to perform maintenance on their existing data collection processes. We work in…
Let’s Build Something Amazing Together
From concept to handoff, we’d love to learn more about what you are working on.
Send us a message below or call us at 1-800-989-6022.