


Protecting Sensitive Data: Ensuring Privacy from a Data Engineering Perspective
August 29, 2024
Protecting Sensitive Data: Ensuring Privacy from a Data Engineering Perspective
In a bank call center, staff members handle clients’ data. They have to identify clients for various requests while maintaining privacy. The call center representative must be able to identify the client while keeping the credit card number private, even though the system holds card information. Protecting sensitive data is crucial for the bank’s success.
You also want to keep the value of transactions on the card private. Data may be substituted with random numbers or displayed as ***, showing only the last four digits for validation purposes.
Now, imagine the same data set is sent to the analytics team to analyze credit card usage by age group and geographic location. You can’t train the model on fictitious data, but you must also hide the actual values. How can you hash the debit amounts so they remain relevant? Whatever model you train on test data must also work well on real data.
What if the source data is so sensitive that you don’t even want it exposed to developers or data engineers?
In a previous blog, we explored strategies and considerations for business owners before granting access to data engineering teams. This blog dives deeper into specific techniques for handling data with personal attributes.
Sensitive Data: What is Personally Identifiable Information (PII)?
To ensure personal information is handled delicately, it must first be identified. Data identifiability is a range – at one extreme, data can help identify an individual directly, while at the other extreme, data is anonymized and cannot be traced back to an individual. Examples of data that can directly identify a person include names, home addresses, phone numbers, email addresses, and social security numbers.
Personal data attributes
Identifying personal attributes within a dataset before utilizing it for analytics is crucial to safeguard individuals’ privacy. There are two main approaches to identifying personal identifiers:
Direct identifiers: This is personal data that can be used to identify an individual without additional information. Examples include:
- Names: Full names or any part of the name that can uniquely identify a person.
- Home Addresses: Specific residential addresses.
- Phone Numbers: Personal phone numbers.
- Email Addresses: Personal email addresses.
- Social Security Numbers (SSNs): Unique identifiers used primarily in the United States. The Canadian equivalent is Social Insurance Numbers (SIN).
Indirect identifiers: This is personal data that can be used to identify an individual when combined with other information. Examples include:
- IP Addresses: Can sometimes identify an individual, especially when combined with timestamps.
- Device Identifiers: Such as MAC addresses or device IDs.
- Partial Identifiers: Last four digits of a social security number, partial home addresses, etc.
- Dates of Birth: When combined with other information.
- Demographic Information: Such as gender, age, or ZIP code
To find personal identifiers in a dataset, you can use a combination of automated tools and manual review:
Automated tools: There are several options on the market to auto-identify PII columns for large datasets. For example, the Microsoft Purview Information Protection scanner can help identify sensitive information within SharePoint document libraries. Microsoft Purview Data Catalog also scans for sensitive information in tables and columns and performs categorization of that information. In addition, it allows for setting custom scanning rules.
Manual review: Even with automated tools, it is essential to manually review the dataset to identify any personal identifiers that may have been missed. Data engineers can review the data elements individually and check if they match any of the examples.
Once personal identifiers have been identified, there are several techniques that can be used to prevent data from being identified with an individual:
- Aggregated Data: Data that has been combined from multiple individuals to show trends without revealing individual identities.
- Anonymized Data: Data that has been stripped of all identifiable information and has undergone processes to prevent re-identification.
- Pseudonymized Data: Data where identifying fields have been replaced with artificial identifiers, though re-identification might still be possible with the correct key.
To ensure data is protected before giving access to developers or analytical teams, it’s crucial to employ methods like anonymization, pseudonymization, synthetic data generation, and hybrid strategies to de-identify the data.
These methods can help eliminate, mask, or conceal sensitive information while retaining the data’s analytical value.
Dynamic masking is a feature of Azure SQL databases that defines a user access policy to mask column data based on the user who is querying the table. This can be used to anonymize credit card numbers, names, addresses, and other identifiable information even before any data is loaded, even from the data engineering team.
Let’s look at examples of the techniques mentioned above, using SQL written by the Data engineering team.
De-identification Techniques for Sensitive Data:
- Data suppression
Data suppression is a data de-identification technique used to protect sensitive information in datasets by removing or hiding certain data elements. Implementing data suppression in SQL involves modifying the database queries to hide or remove specific data elements. Our approach recommends implementing these techniques on views exposed to the analytics team or Power BI views.
Types of Data Suppression:
- Complete Suppression: Entire data entries or specific fields that contain sensitive information are removed from the dataset. For example, removing the exact birthdate from a medical dataset or ssn (Social Security Number).
If you have a table patients and you want to suppress birthdate and ssn, there are 2 options – dropping the columns or sub-selecting other in a view:

- Partial Suppression: Only parts of the data that are too specific and can potentially identify individuals are suppressed. For instance, instead of showing the full address, only the city or postal code is displayed.
To partially suppress data (e.g., masking part of a string):

- Top-coding and Bottom-coding: Data values at the extreme ends of the spectrum are grouped together. For example, ages 90 and above can be grouped and shown as “90+”.
To group data values at the extreme ends:

- Generalization: Replacing specific data with a more general category. For example, instead of displaying a specific salary amount, the data might show a salary range.
To generalize specific data (e.g., replacing exact values with ranges):

Example: Combining Techniques
Here’s a more comprehensive example using a combination of techniques:

The above query:
- Suppresses ages 90 and above by grouping them as “90+.”
- Generalizes salary into ranges.
- Masks the phone number to hide all but the last four digits.
- Excludes employees from the HR department.
- Tokenization
Tokenization is a data de-identification technique that involves replacing sensitive data elements with non-sensitive placeholders called tokens. These tokens can be mapped back to the original data only through a separate secure tokenization system, ensuring the original data remains protected while the tokens can be used in various applications without exposing sensitive information.
Example of Tokenization
Consider a database storing credit card information. When a credit card number is tokenized, the original number is replaced by a token.
Original Data: 1234-5678-9012-3456
Token: TKN-8765-4321-0987-6543
In the database, the credit card number is stored as the token, and the original number is stored securely in a separate token vault.
- Encryption
Encryption is a powerful data de-identification technique that involves converting plaintext data into a coded format (ciphertext) using an algorithm and an encryption key. The ciphertext is unreadable without the corresponding decryption key, which ensures sensitive information remains secure and confidential.
Example of Encryption
Consider encrypting a social security number (SSN) in a database.
Original Data (Plaintext): 123-45-6789
Encryption Key: A secret key used by the encryption algorithm.
Ciphertext: Encrypted version of the SSN, e.g., “Nks9dj2u48==”
In the database, the SSN is stored as the ciphertext. To retrieve and view the original SSN, the decryption key is needed.
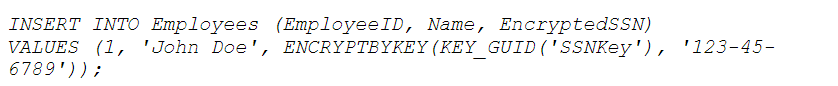
Tokenization vs. Encryption:
- Encryption: Encrypts data using algorithms and keys, making it unreadable without the decryption key. Encrypted data can be reverted to its original form using the key.
- Tokenization: Replaces data with tokens that have no mathematical relationship to the original data. Tokens cannot be reverted to the original data without access to the secure token vault.
While both techniques protect sensitive data, tokenization is often preferred for its simplicity and effectiveness in reducing the scope of compliance audits and the impact of data breaches.
- Synthetic data
Synthetic data is a powerful de-identification technique that involves generating artificial data that mimics the statistical properties of real datasets. The goal is to create a dataset that retains the utility for analysis, machine learning, or testing purposes while ensuring no actual sensitive information is exposed.
Think about it as a randomized dataset. For example, user age is a number between 18 and 100 years normally distributed around mean of original data. In some cases, the data might be a permutation of original data and sometimes just completely made up, it’s common for domains like healthcare to use completely synthetic data for development purposes.
Data Engineering teams often request access to real data, even when synthetic data might suffice. However, it’s important to recognize that synthetic data can be highly effective, particularly during the development and testing stages.
By using synthetic data in these phases, organizations can safeguard sensitive information while still providing engineers with datasets that closely mirror the characteristics of real data.
Relying on synthetic alternatives ensures that data engineers can perform their work effectively without compromising the confidentiality of the data. There is development time needed to synthesize the data but there are some tools available to help generate this data, such as https://generatedata.com/ and Red Gate’s SQL Data Generator.
In a world increasingly focused on data privacy, data suppression emerges as a critical technique for safeguarding sensitive information. Throughout this blog, we’ve explored various de-identification techniques, including data suppression, and their practical implementations to help you protect your data effectively.
By mastering and applying these methods, organizations can navigate the complex landscape of data protection, ensuring that privacy and data utility coexist in harmony.
Looking to protect your data? Our team can help. Fill out the form at the bottom of the page and someone will be in touch. Make sure to subscribe to our blog for more helpful technology tips, tricks, and updates.
Want to hear the latest from out team of experts? Sign up to receive the latest news right to your inbox. You may unsubscribe at anytime.

Discover More

Integration Between Power Platform and SharePoint Encourages Innovation
Organizations are focusing on innovation, streamlining their processes, and delivering better experiences for employees and customers. Power Platform and SharePoint are the Microsoft products that are helping organizations focus on…

Mastering Subagents in VS Code + Copilot: How To Actually Use Them
If you’ve ever dumped a giant problem into Copilot Chat and watched the conversation slowly turn into spaghetti, subagents are the feature you’ve been waiting for. Think of subagents as…

5 Common Misconceptions About Cloud Migration: Debunking the Myths
We’ve all heard of the cloud and cloud migration. But how important is it actually for your business? Organizations are moving to the cloud for several reasons: to improve agility,…

Let’s build something amazing together
From concept to handoff, we’d love to learn more about what you are working on.
Send us a message below or call us at 1-800-989-6022.